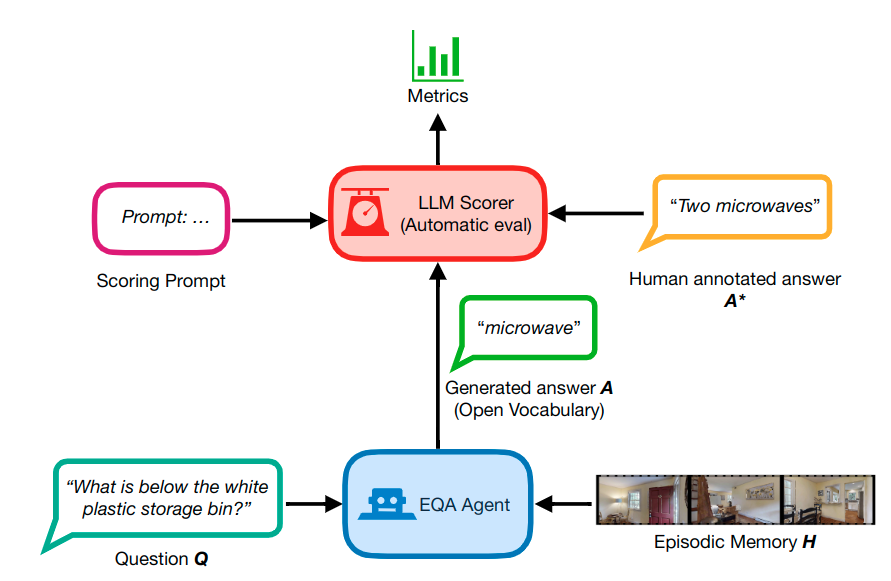
Performance of State-of-the-Art Models

LLM vs. Multi-Modal LLM Performance on EM-EQA. We evaluated several multi-modal LLMs including Claude 3, Gemini Pro, and GPT-4V on OpenEQA. We find that these models consistently outperform text-only (or blind) LLM baselines such as LLaMA-2 or GPT-4. However, performance is substantially worse than the human baselines.